Data Projects
Project 1: Economics Research in the U.S., 1990-2019
With Abhishek Nagaraj
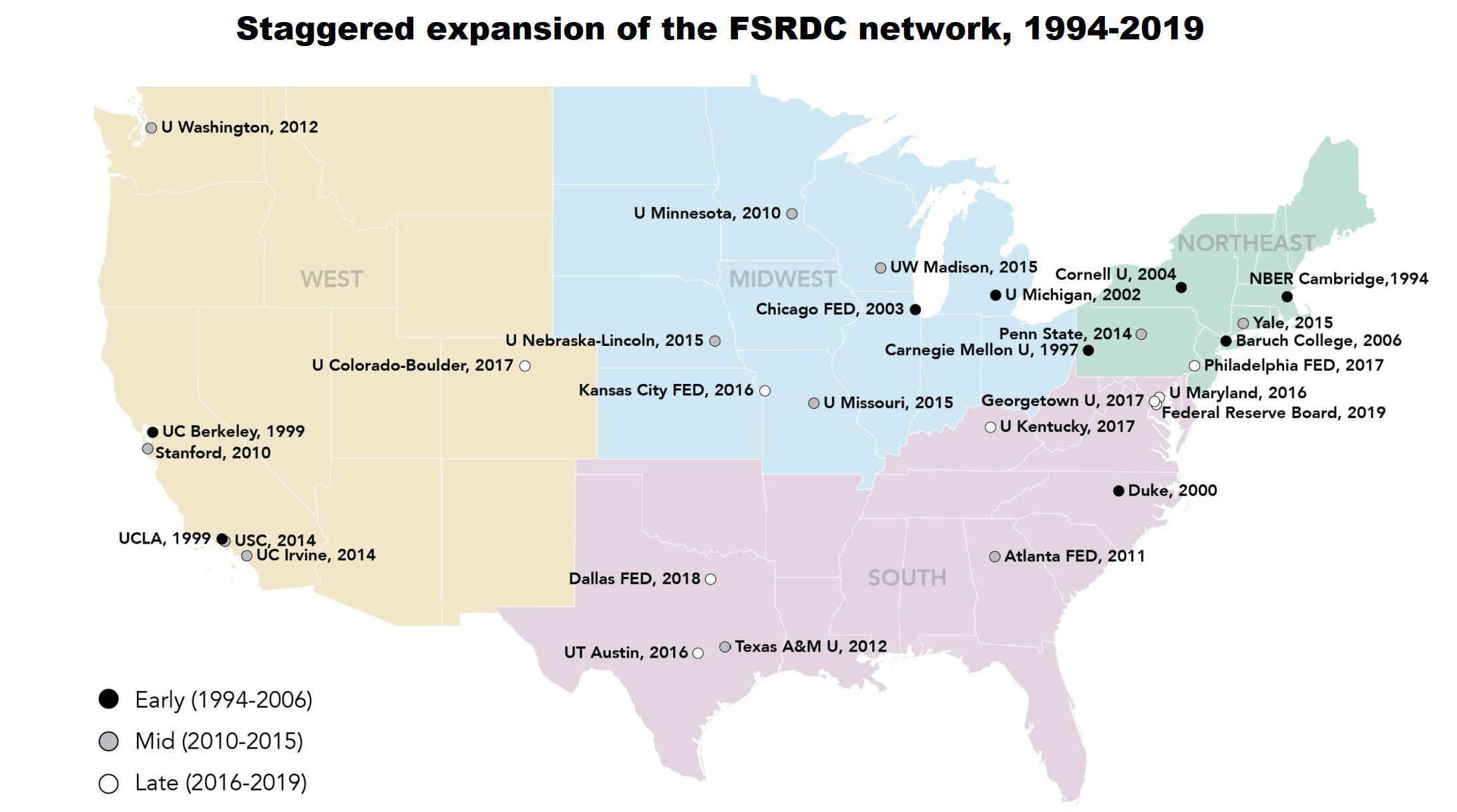
Together with Abhishek Nagaraj, we received a large grant from the Alfred P. Sloan Foundation to build and distribute a comprehensive and disambiguated dataset of 250,000+ economics-related publications by over 19,000 academics affiliated with U.S. research institutions from 1990-2019. This database constitutes a near-census of economic research carried out in the past three decades, integrated with additional information on paper citations and fields. We used this database to estimate the impact of access to Federal Statistical Research Data Centers (FSRDCs) on economic research (Nagaraj and Tranchero, 2024). The descriptive facts emerging from these data are presented in Nagaraj et al. (2025).
Project 2: Knowledge Entities in Pharmaceutical Patents
With Bikash Kumar Panda and Charlie Guthmann
Bikash Kumar Panda, Charlie Guthmann, and I have built a large-scale, open database including all the bio-entities mentioned in USPTO granted patents. We plan to share these data together with a methodological paper that highlights and exemplifies the potential of entitymetrics to measure science-to-technology spillovers. This project was supported by the I3 Open Data Summer Fellows Program.
Project 3: 300 Years of British Patents
With Enrico Berkes and Matthew Lee Chen
Enrico Berkes, Matthew Lee Chen, and I have digitized all the patents granted in England from 1617 to 1899. This period is fascinating and saw momentous economic and social change, encompassing both the First and the Second Industrial Revolution. We believe that the remarkable completeness of the corpus of patent documents will provide a unique lens to understand the determinants of the innovations that enabled modern growth. In particular, we digitized the full specification of each patent, as well as extracted and compiled the disambiguated information about the inventors (including profession and address). This project is an ambitious extension of my Master’s thesis project, which led to the creation of the Bibliographic Composite Index (BCI) of patent quality (Nuvolari et al., 2021). When using the data from "300 Years of British Patents", please cite the companion paper: Berkes et al. (2026).

Matteo Tranchero
Contact
+1 (341) 400-3543 |
mtranc@wharton.upenn.edu
|

Address
The Wharton School of the University of Pennsylvania